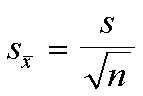Comenzaremos esta entrada definiendo algunos término necesarios:
- Población de estudio: Será el conjunto de pacientes sobre el que queremos estudiar alguna cuestión.
- Muestra: Son el conjunto de individuos que participan en el muestreo.
- Tamaño muestral: Es el número de individuos que forman la muestra.
- Inferencia estadística: Son los procedimientos estadísticos que nos permitirán pasar de lo particular, la muestra, a lo general, que es la población.
- Técnica de muestreo: Son los procedimientos que nos permiten elegir muestras de forma adecuada, es decir que reflejen las características de la población.
- Muestreo probabilístico o aleatorio: Es la muestra elegida por un proceso al azar.
- Error aleatorio: Es el erro que irá asociado a la muestra que ha sido elegida mediante un proceso de azar.
Proceso de la inferencia estadística:

Se hace una selección aleatoria de una población de estudio y de ahí se obtiene la muestra, la medida de la variable de estudio que hemos obtenido será el estimador, a partir del estimador, mediante un proceso llamado inferencia, me acercaré al parámetro, que será la variable que queremos medir en la población.
Error estándar:
Se trata de una medida cuya función es mostrar la variabilidad de los valores del estimador, que será la media o una proporción. Mientras menor sea este error estándar más fiable será el valor de nuestra muestra. Se calcula de la siguiente manera:
-Para una media: -Para una proporción:
 Intervalos de confianza:
Intervalos de confianza:
Los utilizaremos para conocer el parámetro en una población , midiendo el error aleatorio. Nos dará dos números, con un nivel de confianza determinado, dentro de los cuales podemos decir que se encuentra el x% de nuestra población. La formula será:
- I.C. de un parámetro=estimador+/- Z*(e. éstándar)
Técnicas de muestreo:
Un muestreo es un método por el cual podremos coger un grupo pequeño de una población, teniendo un grado de probabilidad de que este grupo posea las características de la población que estamos estudiando.
Tipos de muestreo:
-Muestreo Probabilístico: Todos los elementos tendrán la misma probabilidad de ser elegidos.

- Aleatorio simple:Cada unidad tiene una probabilidad equitativa de ser incluida en la muestra. Podrá ser de sorteo,el cual no podrá aplicarse a poblaciones muy grandes o por una tabla de número aleatorios.
- Aleatorio sistemático:Será parecido al simple, todos los individuos tendrán la misma posibilidad de ser selccionados. Las elegiré ordenándolas y escogiéndolas mediante un intervalo, ej: 10,20, 30,40...
- Estratificado:Se subdivirá la población en estratos, debido a que las variables deberán someterse a estudio.
- Conglomerado:En la selección en lugar de escoger una unidad se escogerán grupos o conglomerados.
-Muestreo no Probabilístico: Será aquel que no sigue el proceso aleatorio.
- Por cuotas: El investigador seleccionará la muestra teniendo en cuenta algunos fenómenos o variables a estudiar.
- Accidental:Se utilizará a las personas disponibles en un momento dado, según lo que interese estudiar.
Tamaño de la muestra:
Será el número mínimo de individuos que necesitamos en la muestra para realizar la investigación. Éste dependerá del error estándar, de la variabilidad de la variable a estudiar, del tamaño de la población... su formula será:
Tras calcular el tamaño de la muestra habrá que comprobar si es el valor correcto mediante:
- N> n*(n-1) Si no se cumple habrá que calcular n mediante el cálculo de n´:
-n´= n/1+ (n/N)
Sin embargo cuando queramos calcular el tamaño de una muestra cuando queremos estimar una proporción usaremos la siguiente fórmula: